Should I Have My Radiators Flushed?
Fleeting- see,
I’ve been told to flush them every 10 years. But it’s also said that they should be flushed if the temperature difference between the top and bottom is significant.
Here, “significant” is pretty vague. Let’s consider that 5°C of difference is a good start and definitively 10°C says that we have to do something right now!
This winter, I installed a Zigbee sensor on the top of a radiator and one on the bottom. Let’s see what the results are.
First, let’s get the data out of my database and perform a little bit of cleanup and formatting to ease playing with the data.:
from redis import StrictRedis
import pandas as pd
from datetime import datetime
d = StrictRedis()
t = d.ts()
top = pd.DataFrame(t.range("zigbee.RadiatorTop", int(datetime.strptime("2024-01-23", "%Y-%m-%d").timestamp() * 1000), int(datetime.strptime("2024-03-01", "%Y-%m-%d").timestamp() * 1000)))
bottom = pd.DataFrame(t.range("zigbee.RadiatorBottom", int(datetime.strptime("2024-01-23", "%Y-%m-%d").timestamp() * 1000), int(datetime.strptime("2024-03-01", "%Y-%m-%d").timestamp() * 1000)))
top.columns = ['time', 'top']
bottom.columns = ['time', 'bottom']
top = top.set_index('time')
bottom = bottom.set_index('time')
r = pd.concat([top, bottom])
r.index = pd.to_datetime(r.index, unit="ms")
r = r.sort_index()
# remove the days we were out of the home and the radiator were off
r = r[(r.index < '2024-02-17') | (r.index > '2024-02-23')]
# let's try hard to have values for both top and bottom at each point in time, so that we can compare them
r = r.interpolate(method='polynomial', order=5).dropna()
file = "/tmp/radiator.csv"
r.to_csv(file)
return file
https://konubinix.eu/ipfs/bafybeib7nacfjayqutve75blqlrni6xg3iilssudn5atziyvur6xxm5nm4
This is the data I will use hereafter.
Let’s load it.
import pandas as pd
r = pd.read_csv(file, parse_dates=["time"], index_col="time")
print(r)
top bottom
time
2024-01-22 23:12:02 30.180000 25.047615
2024-01-22 23:15:29 29.770144 24.630000
2024-01-22 23:22:02 29.190000 24.002997
2024-01-22 23:25:56 28.872237 23.710000
2024-01-22 23:31:53 28.370000 23.250299
... ... ...
2024-02-29 22:43:00 34.462688 28.970000
2024-02-29 22:44:09 34.290000 28.825460
2024-02-29 22:48:37 33.702131 28.320000
2024-02-29 22:49:07 33.650000 28.267985
2024-02-29 22:53:37 33.300166 27.670000
[6124 rows x 2 columns]
Let’s try to simply plot them to have a feeling of how they look like.
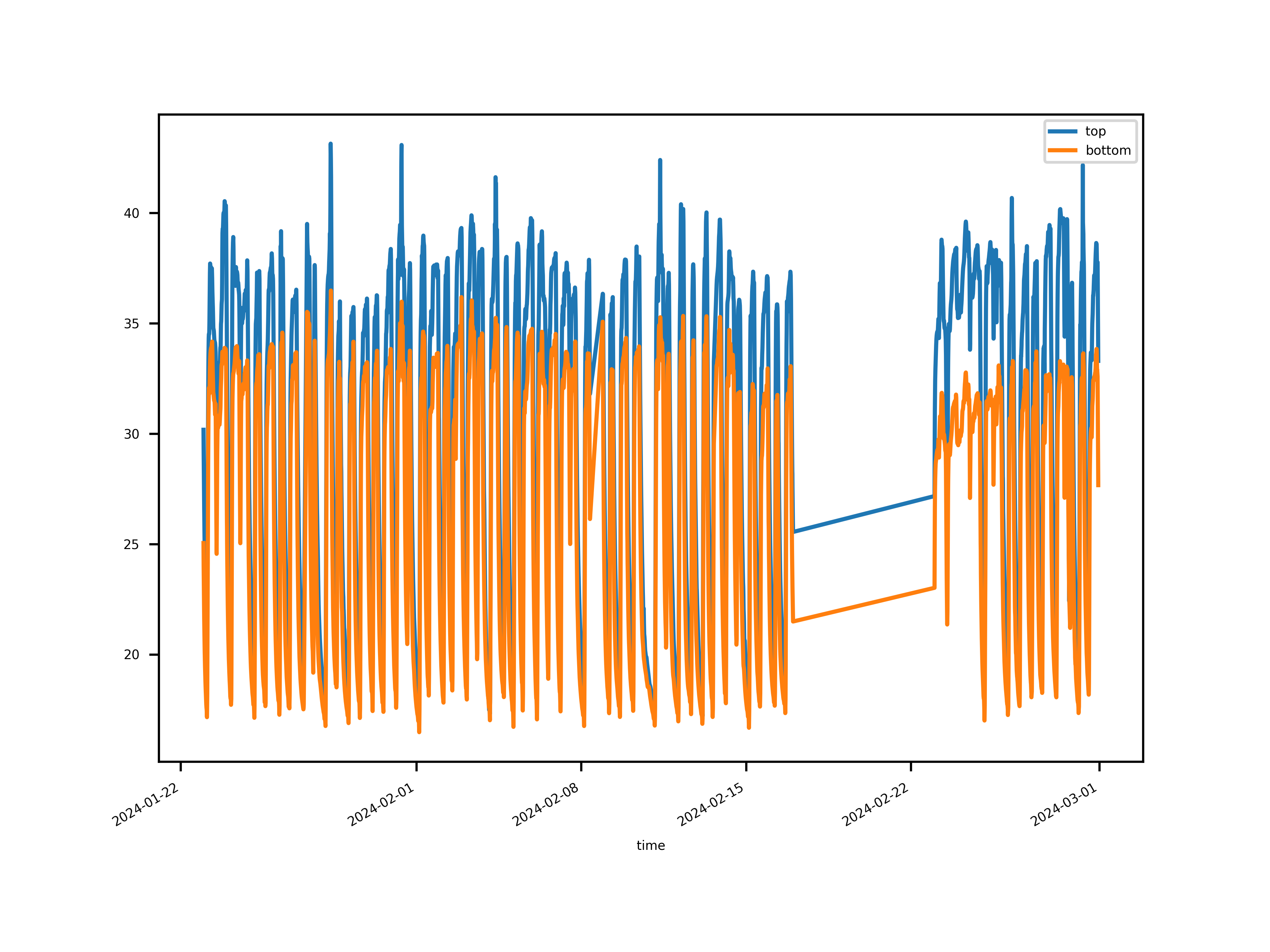
The data looks clean.
from pathlib import Path
out=Path("/tmp/plot.html")
import plotly.io as pio
variable=locals()[var]
function=variable.__getattr__(fct)
kwargs={
"backend":"plotly",
}
if marker:
kwargs["markers"] = True
out.write_text(
pio.to_html(
function(**kwargs)
)
)
print(out)
In case I want to get a deeper interactive look at the data, I will also provide a plot made with plotly.
look at outliers
One of our hypothesis is that sludge is supposed to cause the bottom part of the radiator to be significantly colder than the top, as the sludge hinders the flow of water. The water will simply flow were the sludge is not, hence at the top.
Let’s find out whether that hypothesis holds.
print(r[r.bottom > r.top])
top bottom
time
2024-02-04 02:14:42 17.486029 17.620000
2024-02-04 02:30:59 17.490000 17.739859
2024-02-28 17:13:05 22.417144 22.810000
2024-02-28 17:19:12 22.420000 22.614221
Hmm, that’s not bad. But there are still two outliers. Let’s take a look at them.
First, at about , something apparently went wrong.
a = r["2024-02-04 00:00":"2024-02-04 04:00"]
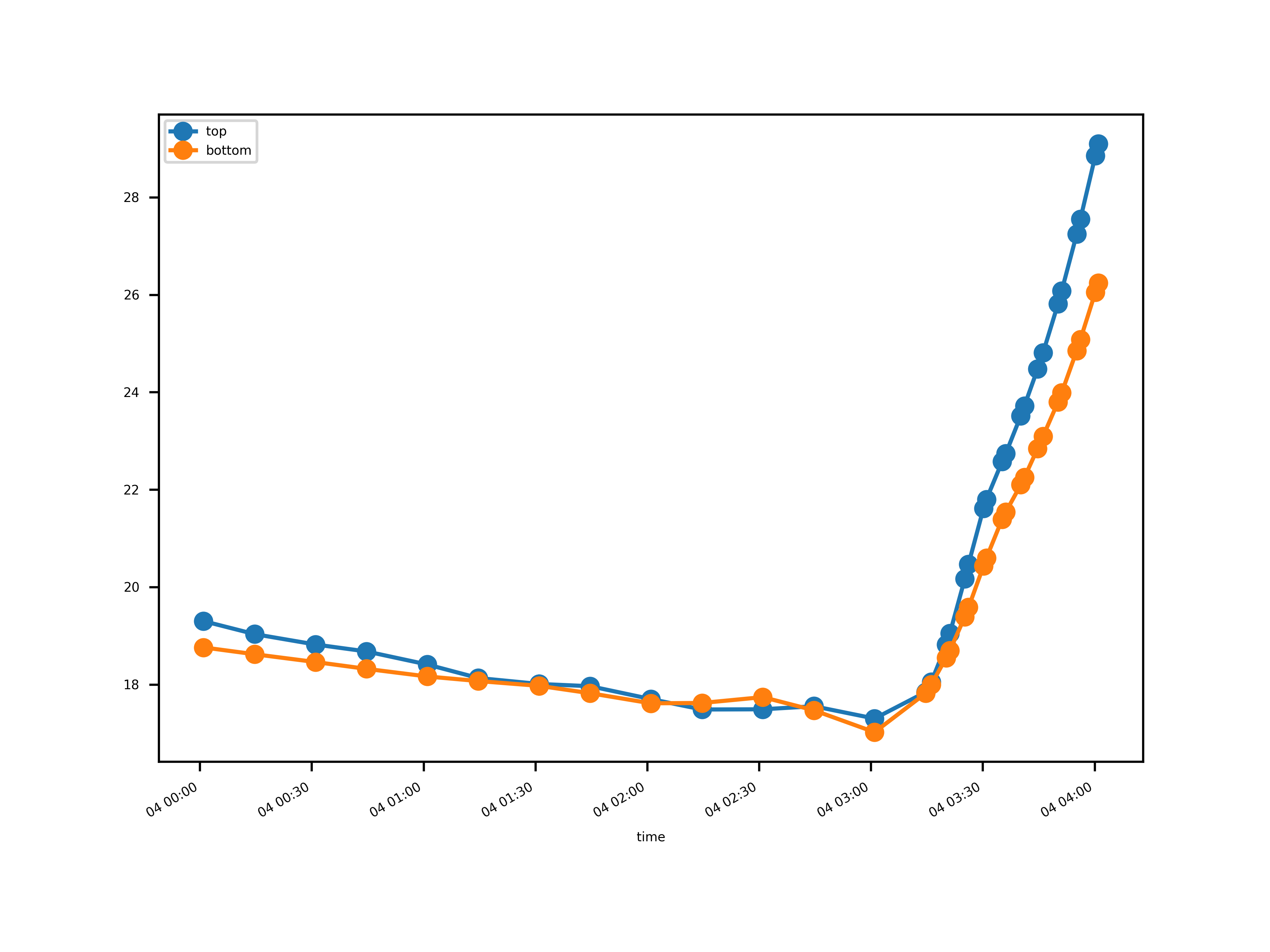
This is strange. The values are pretty close, so maybe this goes into simple precision errors. I think this one won’t harm the analysis.
The second one occurs at .
a = r["2024-02-28 17:00":"2024-02-28 18:00"]
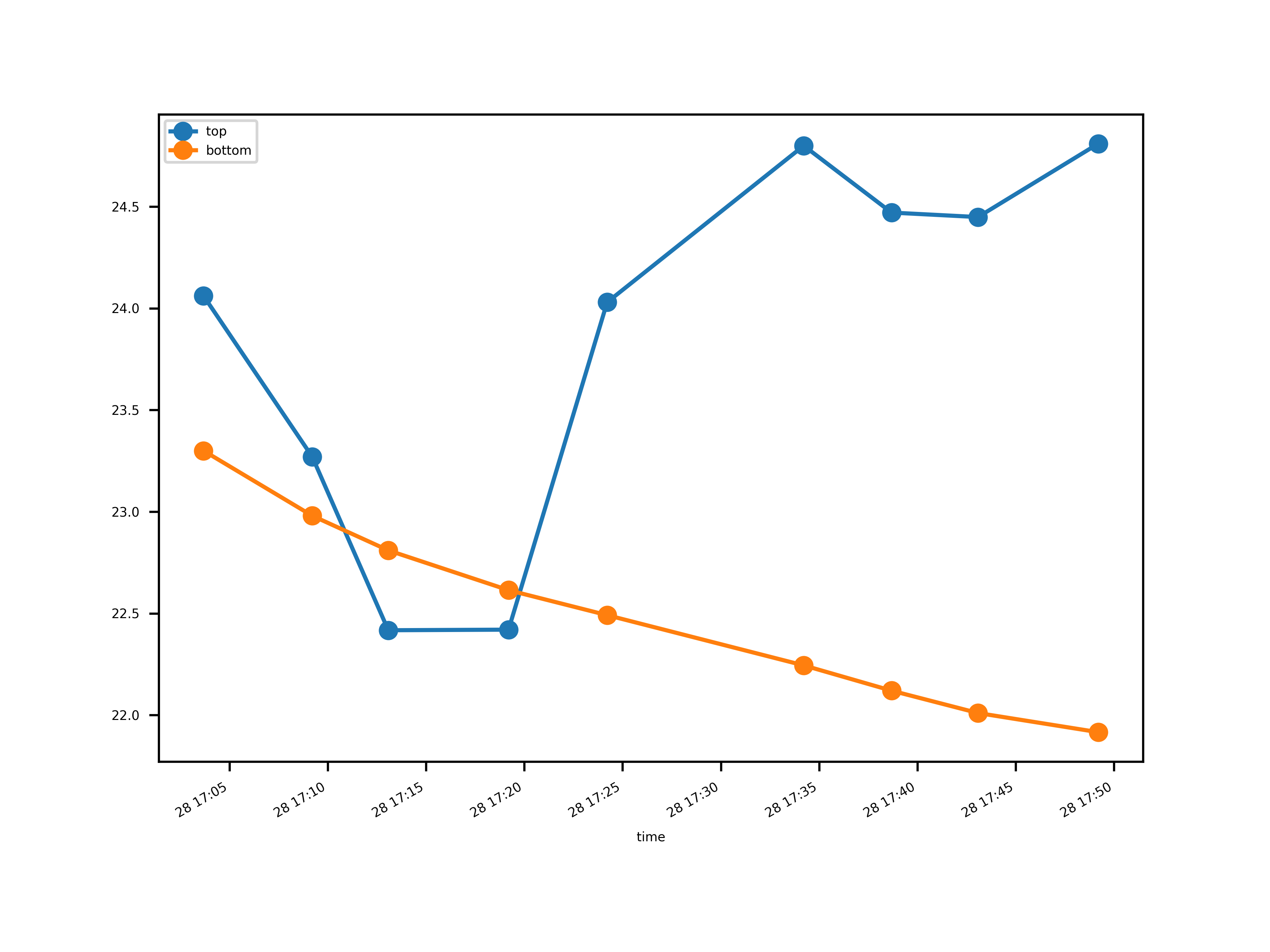
The temperature of the top probe suddenly drops before getting back to normal. This is most likely the effect of opening the window. I can assume that at that time, we had to open them for a little while, like for cleaning them. Again, it does not seem that problematic, so let’s keep it that way.
analysis
r.describe()
top bottom
count 6124.000000 6124.000000
mean 30.355279 26.400982
std 6.203890 5.397042
min 17.212234 16.480128
25% 24.970635 21.350000
50% 31.500000 27.006118
75% 35.810000 31.400295
max 43.140000 36.485341
The data are pretty close, let’s take a look at the difference.
a = (r.top - r.bottom)
a.describe()
count 6124.000000
mean 3.954297
std 1.397309
min -0.392856
25% 3.028367
50% 3.930668
75% 4.894372
max 9.447843
dtype: float64
This indicates that, for the most part, the top part is around 4°C hotter than the bottom part.
The mean and the median are very close, indicating a symmetry.
It might be easier to see this visually.
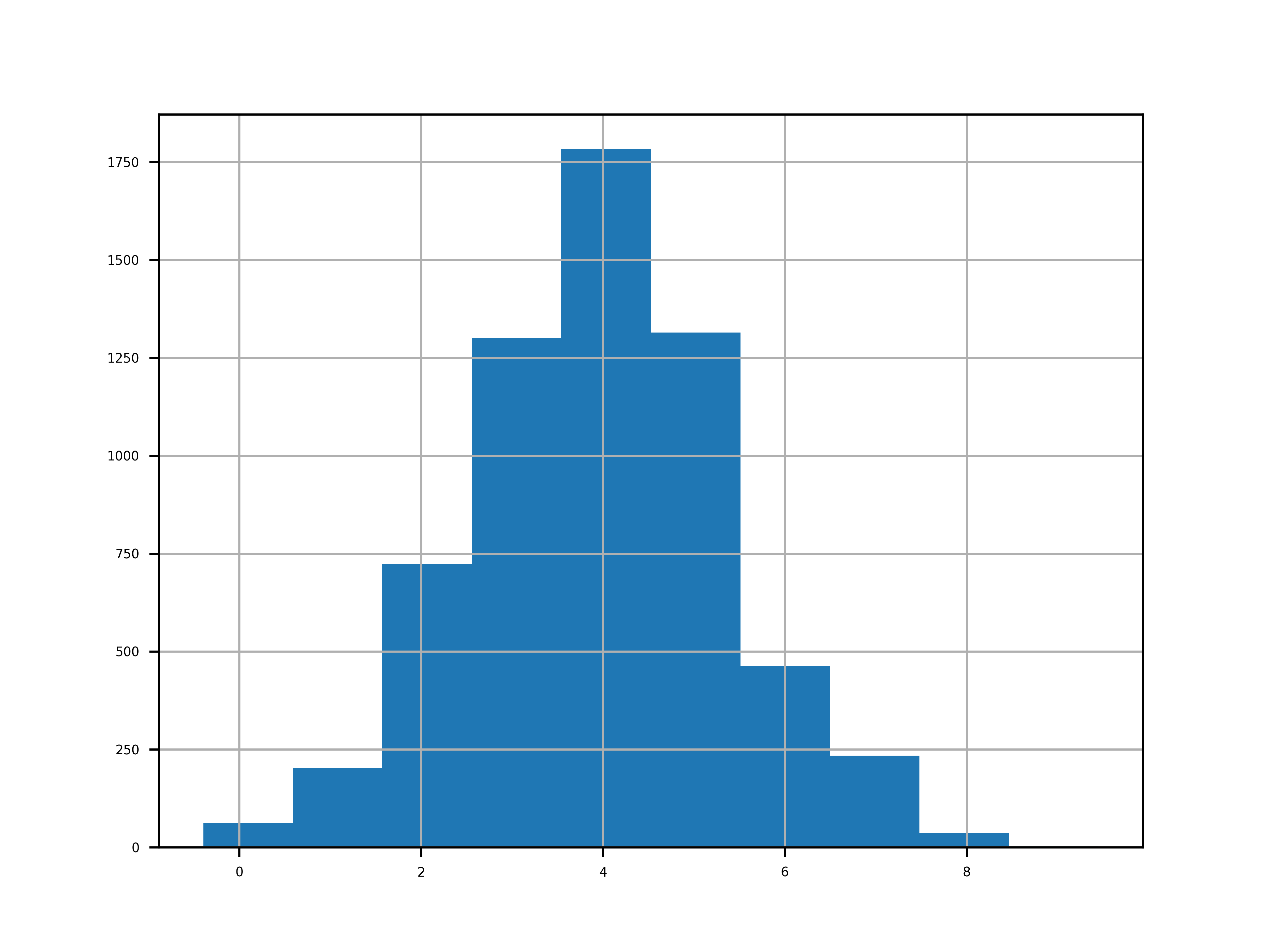
And the same with plotly (just for fun).
We can see what the data indicated: The hot part being about 4°C hotter for the most part.
conclusion
We decided that if the top part would be more than 5°C hotter than the bottom one, we would consider flushing the radiators.
This in not the case this year. Therefore, without a good reason to believe, we claim that this is not needed (this year).