Event Sourcing, CQRS, Stream Processing and Apache Kafka: What’s the Connection?
Fleeting- External reference: https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/
Event sourcing, CQRS, stream processing and Apache Kafka: What’s the connection? - Confluent
— https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/
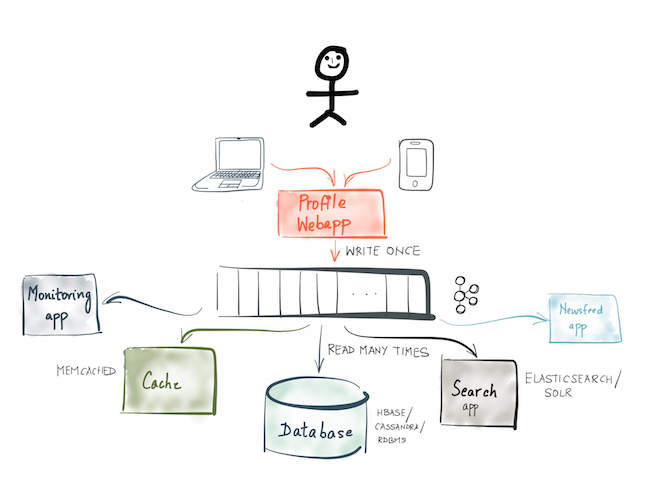
Event sourcing involves modeling the state changes made by applications as an immutable sequence or “log” of events
— https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/
storing the event that triggers the state change in an immutable log and modeling the state changes as responses to the events in the log
— https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/
Kafka is a high-performance, low-latency, scalable and durable log
— https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/
CQRS involves splitting an application into two parts internally — the command side ordering the system to update state and the query side that gets information without changing state
— https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/
CQRS has a few advantages — It decouples the load from writes and reads allowing each to be scaled independently
— https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/
The read store can be optimized for the query pattern of the application; a graph application can use Neo4j as its read store, a search application can use Lucene
— https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/