An entity capable of granting access to a protected resource.
When the resource owner is a person, it is referred to as an
end-user.
resource server
The server hosting the protected resources, capable of accepting
and responding to protected resource requests using access tokens.
client
An application making protected resource requests on behalf of the
resource owner and with its authorization. The term “client” does
not imply any particular implementation characteristics (e.g.,
whether the application executes on a server, a desktop, or other
devices).
authorization server
The server issuing access tokens to the client after successfully
authenticating the resource owner and obtaining authorization.
obtain an authorization grant from the resource owner
in order to gain an access token against the authorization server
so as to get access to the resources
of the resource owner
from the resource server.
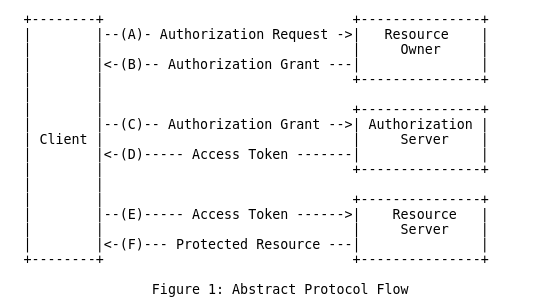
This abstract flow is defined like this:
(A) The client requests authorization from the resource owner. The
authorization request can be made directly to the resource owner (as shown),
or preferably indirectly via the authorization server as an intermediary.
(B) The client receives an authorization grant, which is a credential
representing the resource owner’s authorization, expressed using one of four
grant types defined in this specification or using an extension grant type.
The authorization grant type depends on the method used by the client to
request authorization and the types supported by the authorization server.
(C) The client requests an access token by authenticating with the
authorization server and presenting the authorization grant.
(D) The authorization server authenticates the client and validates the
authorization grant, and if valid, issues an access token.
(E) The client requests the protected resource from the resource server and
authenticates by presenting the access token.
(F) The resource server validates the access token, and if valid, serves the
request.
confidential clients can store the user credential and only need to get the authorizations from the authorization server,
public clients cannot and need the authorization server to perform the login.
In the later, it means that in the flow, the user is asked to login into the
authorization server and then the client is given the access token (more on
that token later).
It explains that the three following use cases1 where driving this specification:
an old school web application, where the server can connect to the
authorization server and then is confidential,
a new style web application, where the logic is executed browser side, hence
considered not trust worthy and public,
a native application, where the logic is also executed in the user device,
hence also considered not trust worthy and public,
Each client is given a client identifier by the authorization server. This
identifier is not a secret. For confidential clients, a client secret is also
given that allows the client to authenticate. It is said that public client may
have a client secret, but that the authorization server should not actually
take this into account, due to the non trust worthiness of the client.
There are 4 ways2 to have the resource owner grant, most of which use HTTP redirection:
authorization code: redirecting the user to an authorization server to log in
and redirect back to the client. It is optimized for confidential clients as
it assumes the client is secure enough to store its refresh token,
implicit: like the authorization code, but the client is directly given the
access token instead of being redirected. This only makes sense when the
client is implemented in a browser native language, such as javascript. It
exists so as to make the client slightly more responsive, while it is less
secure because there has been no intermediary authorization server to
authenticate the user. It is optimized for public clients as it does not
provide a refresh token and force the client to register anew often.
resource owner user and password3: is considered a least preferred choice4 and
assumes the resource owner trusts the client for not stealing or leaking per
credentials.
client credential: is a lot alike 3, but when the client is only used by one
user, and then there is no need to have a user credential. In that case, the
client identification is enough. It makes sense when the resource are
actually under the exclusive control of the client.
In any case, the client eventually get an access token, that can be used to get
access to the resource. The access token is considered ephemeral. This provides
a mean to easily revoke ones right by the non possibility of getting a new fresh
access token. To help refreshing the access token without getting through the
whole grant flow, the authorization server may provide a refresh token that can
be used in the future to claim for a new fresh access token.
When asking for an access token, the client provides a wanted scope. The
authorization server may ignore some of this scope and eventually returns the
scope for which the token is issued. What this scope gives access to is beyond
the scope of the specification (pun intended).
In this specification, the access token is a short lived so-called bearer token.
There is nothing in OAuth 2.0 against putting some information into the
bearer token issued by the authorization server.
Even though JWT, JOSE header, JWS and JWE are defined in separate standards,
they overlap and depend on each other. We can easily understand that they all
combine to provide this concepts of a self-encoded access tokens.
JSON web tokens is a format to encode claims (a.k.a. key value pairs telling
something about the resource owner). JWS Compact Serialization is the way to put
this data into a URL (required by OAuth 2.0). This also appears to be the reason
why claims must be as short as possible and the standardized claims have keys of
only 3 characters (iss, sub, aud, exp,…).
JOSE header is defined in JWS (in here)
and JWE (in here). It is a standard of encoding in json the information about
how to use the JWS or JWE payload. It contains the type of the payload and the
signature/encryption algorithms and hashes to use.
JSON Web Signature describes how to concatenate a JOSE header, a payload
and a signature, encoded in base64 and then separated with spaces.
You can easily take a look at a JWS in the site https://jwt.io. By the way, the
fact that this site is called JWT but actually shows JWS data is a sign that all
those concepts are not meant to be thought separately. Therefore, when people
talk about JWT, they often mean a JWS compactly serialized payload encoded in
JWT (see also should I say JWT or JWT token, or JWS token or…?)
Hence, for example, the following JWS data, signed with the secret “test”.
Can easily be processed with the following python code
As stated in the appendix C, they don’t provide base64 padding, hence we
artificially add an extra padding of “=” to make python implementation accept
those base64 encoded content. Also, they replace the + and / character of the
base64 alphabet respectively with - and _. This makes sense, as this content will eventually
be put into a URL, but one could ask why not using a more URL friendly encoding,
like base58 or base32.
Therefore the python code to read such data should be like:
OpenID connect appears to be a specification that describes how to use OAuth
2.0 to get not only an access token, but also a so called Identity Token. This
identity token is actually a a JWS token in which the JWT claims are user
data.
The scope of OAuth 2.0 is used to define what data to return in the id token.
In order to get the id token along with the access token, the client needs to
explicitly ask for the scope openid.
The authorization servers that talks OpenID connect language are called OpenID
providers. They are implementations of the IdP concept. Also, the OAuth 2.0
client is referred to as the Relying Party.
This specification also tackle other topics, like OpenID Connect Provider
discovery, but that goes beyond the scope of what I think I need to
understand so far.
Keycloak, finally
Keycloak is the Identity Provider, it provides the way to specify how to
log in, possibly using stuff like TOTP and return signed access tokens
that can be used by the applications to give the client access to the
resources of the resource owner.
As an openid provider
When configured in OpenID Connect mode, keycloak becomes an OpenID Provider.
We can connect and get an access token and a refresh token.
We can see that the “typ” is Bearer, meaning “don’t try to interpret the
content, I’m just a token to authenticate”, but the other claims contains much
information about the user, like an OpenID Token would do.
Actually, the same information is provided. The only difference appears to be
that “typ” is now ID, the “aud” is now the client id (meaning that the id token
is meant to be used by the client and not the resource server5) and all the
keycloak specific stuff are gone.
Then, one may naively think that if one needs to get the official client id as
per the specification, the scope=openid is needed, but if the purpose is to get
user information, the access_token could be more than enough.
Actually, they are conceptually different, so I would recommend to use one or
the other depending on the goal to reach and the expected piece of code that is
supposed to interpret it. The client is supposed to interpret the ID Token,
while the access token is supposed to make sens only for the resource server
(see ID Tokens vs Access Tokens). Therefore, the client should not make any
assumption about what is inside the access token and use the id token to find
user information.
Also, this data is signed using RSA, as the JOSE header indicates.
In case the signature would have failed, python-jose would have raised an error.
Describing roles and scopes and mapping
In keycloak, the users are part of groups that share the same attributes.
The oauth 2.0 scopes (called client scope in keycloak) are associated with
mappers that describes what user/group attribute will be returned in the
claims and how they will be returned.
You can define those mappers the scope and then associate a client scope to a
client, or directly create a mapper inside a client.
Those mappers can be of a lot of kind, and use a lot of sources of user
information (like group, roles) as input. They eventually provide the claims
to put in the access token. It is to be noted that it is asked whether to
provide this information in the id token or in the access token or not.
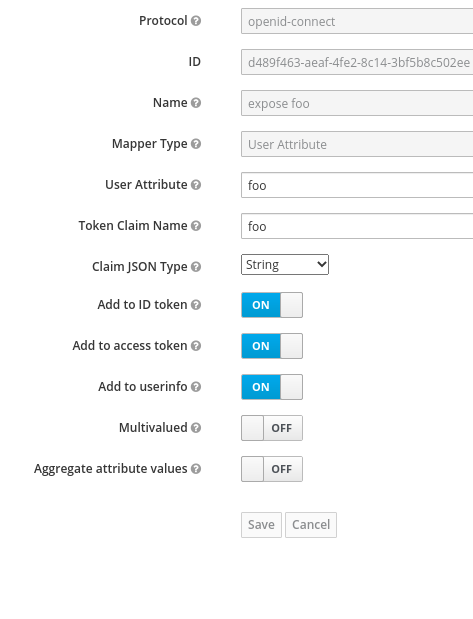
For example, say you add the attribute foo=bar in the user test.
Then, in the client Mapper, you add one that reads the value of foo.
Then you will see the this data in the access token.
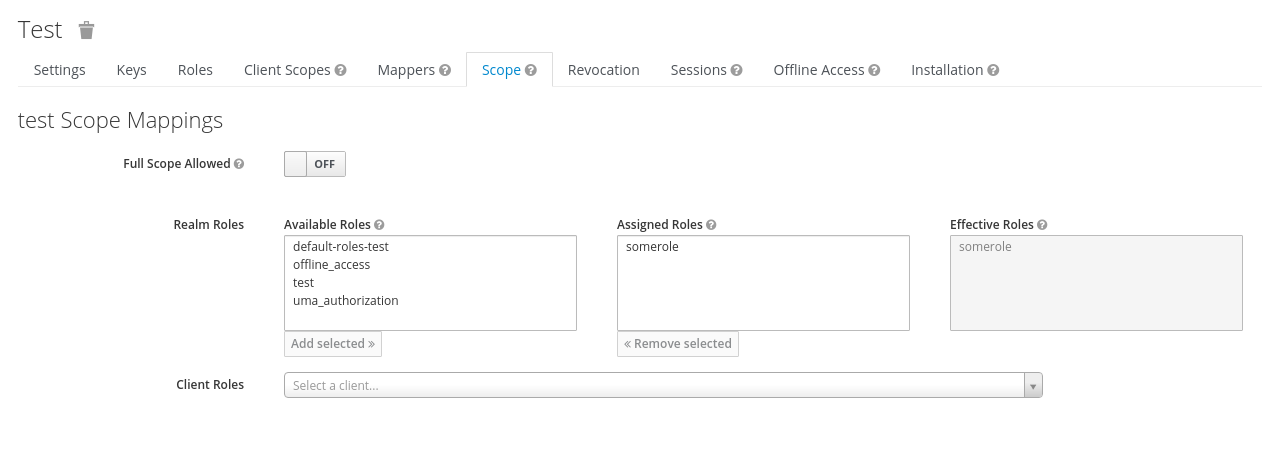
The access token returned by keycloak will return the roles associated with
the user. This can be filtered using the “scope” tab of the client, thus
limiting the returned roles to only those that make sense for the client.
Thus, by providing this scope limitation in the client.
It comes from the default configuration of the client scopes. By default, a
new client comes with the client scope role, that provides, among other
things, a mapper called “client roles”.
This mapper provides the token claim “resource_access.${client_id}.roles”. So
that data apparently comes from a client called “account” that would provides
roles.
And we indeed can find the client named account with, among others, those
roles configured.
By adding the user to some of the other roles, we can see them appear in the
answer. Those three roles (manage-account, manage-account-links and
view-profile) where shown by default because they are defined as default
roles for the account client. This is difficult to find out because it is not
in the client configuration panel, but in the role panel, when asking
explicitly for the default roles of this client.
How do I use this in real life?
Now that I understand what are jwt, jws, oauth 2.0, openid connect and
keycloak and how keycloak works, I need to decide how I want to make the whole
stuff work.
Actually, I did not find any resource or standard explaining a “correct” way
of making the whole thing.
But I feel like it most cases using keycloak in an openid connect fashion, the
paradigm is to let keycloak provide the tokens describing the user roles and
let the resource server decide what kind of resources to serve based on that
information.
So, I guess the usage I would be:
use keycloak in openid-connect mode,
describe roles that indicate what one can do about the resource
A web application is a confidential client running on a web
server. Resource owners access the client via an HTML user
interface rendered in a user-agent on the device used by the
resource owner. The client credentials as well as any access
token issued to the client are stored on the web server and are
not exposed to or accessible by the resource owner.
user-agent-based application
A user-agent-based application is a public client in which the
client code is downloaded from a web server and executes within a
user-agent (e.g., web browser) on the device used by the resource
owner. Protocol data and credentials are easily accessible (and
often visible) to the resource owner. Since such applications
reside within the user-agent, they can make seamless use of the
user-agent capabilities when requesting authorization.
native application
A native application is a public client installed and executed on
the device used by the resource owner. Protocol data and
credentials are accessible to the resource owner. It is assumed
that any client authentication credentials included in the
application can be extracted. On the other hand, dynamically
issued credentials such as access tokens or refresh tokens can
receive an acceptable level of protection. At a minimum, these
credentials are protected from hostile servers with which the
application may interact. On some platforms, these credentials
might be protected from other applications residing on the same
device.
An authorization grant is a credential representing the resource
owner’s authorization (to access its protected resources) used by the
client to obtain an access token
The credentials should only be used when there is a high
degree of trust between the resource owner and the client (e.g., the
client is part of the device operating system or a highly privileged
application), and when other authorization grant types are not
available (such as an authorization code)